Evaluation Metrics for Classification Problem You Should Know with Python Implementation
A classifier is only as good as the metric used to evaluate it.
Evaluating a model is a major part of building an effective machine learning model. The most frequent classification evaluation metric that we use should be ‘Accuracy’. You might believe that the model is good when the accuracy rate is 99%! However, it is not always true and can be misleading in some situations.
When it comes to classification, there are four main types of classification tasks that you may encounter; they are:
- Binary Classification
- Multi-Class Classification
- Multi-Label Classification
- Imbalanced Classification
Binary Classification
Binary classification refers to those classification tasks that have two class labels.
Examples include:
- Email spam detection (spam or not).
- Review prediction(positive or negative).
- Cancer prediction (yes or not).
Multi-Class Classification
Multi-class classification refers to those classification tasks that have more than two class labels.
Examples include:
- Face classification.
- Plant species classification.
- Optical character recognition.
Multi-Label Classification
Multi-label classification refers to those classification tasks that have two or more class labels, where one or more class labels may be predicted for each example.
Consider the example of photo classification, where a given photo may have multiple objects in the scene and a model may predict the presence of multiple known objects in the photo, such as “bicycle,” “apple,” “person,” etc.
Another example is the movie genre. A single movie can have more than one genre like “comedy”, “romance”, “horror” etc.
Imbalanced Classification
Imbalanced classification refers to classification tasks where the number of examples in each class is unequally distributed.
Typically, imbalanced classification tasks are binary classification tasks where the majority of examples in the training dataset belong to the normal class and a minority of examples belong to the abnormal class.
Consider the example of credit card fraud detection, where very few fraud transactions happened so class ‘fraud’ is very rare (minority class) compare to the ‘not fraud’ class.
The short introduction for classification is over Now we move to the actual topic.
Warming up: The flow of Machine Learning model
In any binary classification task, we model can only achieve two results, either our model is correct or incorrect in the prediction where we only have two classes. Imagine we now have a classification task to predict if an image is a dog or cat. In supervised learning, we first fit/train a model on training data, then test the model on testing data. Once we have the model’s predictions from the X_test data, we compare it to the true y_values (the correct labels).

We feed the image of the dog into our trained model before the model prediction. The model predicts that this is a dog, and then we compare the prediction to the correct label. If we compare the prediction to the label of “dog,” it is correct. However, if it predicts that this image is a cat, this comparison to the correct label would be incorrect.
We repeat this process for all the images in our X_test data. Eventually, we will have a count of correctly matched and a count of incorrect matches. The key realization is that not all incorrect or correct matches hold equal value in reality. Therefore a single metric won’t tell the whole story.
As mentioned, accuracy is one of the common evaluation metrics in classification problems, that is the total number of correct predictions divided by the total number of predictions made for a dataset. Accuracy is useful when the target class is well balanced but is not a good choice with unbalanced classes. Imagine we had 99 images of the dog and only 1 image of a cat in our training data, our model would be simply a line that always predicted the dog, and therefore we got 99% accuracy. Data is always imbalanced in reality, such as Spam email, credit card fraud, and medical diagnosis. Hence, if we want to have a full picture of the model evaluation, other metrics such as recall and precision should also be considered.
Let’s Start with different evaluation metrics,
1. Confusion Matrix, Accuracy, Precision, and Recall:
A. Confusion Matrix:
Evaluation of the performance of a classification model is based on the counts of test records correctly and incorrectly predicted by the model. The confusion matrix provides a more insightful picture which is not only the performance of a predictive model, but also which classes are being predicted correctly and incorrectly, and what type of errors are being made.

Confusion Matrix for Multi-class classification :

B. Accuracy :
Accuracy is the quintessential classification metric. It is pretty easy to understand. And easily suited for binary as well as a multiclass classification problem.
Accuracy = (TP+TN)/(TP+FP+FN+TN)
In other words, Accuracy = (sum of diagonal elements of confusion matrix)/(sum of all elements in confusion Matrix)
Accuracy is the proportion of true results among the total number of cases examined.
When to use?
Accuracy is a valid choice of evaluation for classification problems that are well balanced and not skewed or No class imbalance.
Caveats
Let us say that our target class is very sparse. Do we want accuracy as a metric of our model performance? What if we are predicting credit card fraud transactions? (out of 1000 transactions we found only 2 fraud transactions) Just say ‘Not Fraud’ all the time. And you will be 98% accurate. My model can be reasonably accurate, but not at all valuable.
So Accuracy is not a good measure when a class imbalance occurs!
B. Precision:
Let’s start with precision, which answers the following question: what proportion of predicted Positives is truly Positive?
Or in other words, Out of all predicted positive class by model how many are actually(truly) positives (TP)
Precision = (TP)/(TP+FP)
When to use?
Precision is a valid choice of evaluation metric when we want to be very sure of our prediction. For example: If we are building a system to predict if we should decrease the credit limit on a particular account, we want to be very sure about our prediction or it may result in customer dissatisfaction.
C. Recall
Another very useful measure is recall, which answers a different question: what proportion of actual Positives is correctly classified?
Or in other words, Out of all positive classes how many actually(truly) positives (TP) predicted by the model.
Recall = (TP)/(TP+FN)
When to use?
Recall is a valid choice of evaluation metric when we want to capture as many positives as possible. For example: If we are building a system to predict if a person has cancer or not, we want to capture the disease even if we are not very sure.
This seems too theoretical, Now will see an example to illustrate the above metrics,
Case-1: COVID test prediction (cost of FN > cost of FP)
class 1: COVID
class 0: Healthy
- the result of TP will be that the COVID 19 residents diagnosed with COVID-19.
- the result of TN will be that healthy residents are in good health.
- the result of FP will be that those actually healthy residents are predicted as COVID 19 residents.
- the result of FN will be that those actual COVID 19 residents are predicted as the healthy residents
In case 1, which scenario do you think will have the highest cost?
Imagine that if we predict COVID-19 residents as healthy patients and they do not need to quarantine, there would be a massive number of COVID-19 infections. The cost of false negatives is much higher than the cost of false positives.
Let’s take an example, We trained three Models on the COVID-19 dataset. Now we have to test which model is better on 10 test samples that we collect. These three models will predict classes for 10 samples, So we have 10 ground truth(y_true) and predicted target labels as y_predict as shown in the below code,


From the above code, we can see that as FN Increases Recall decreases as the recall depends on FN. So recall is the best metric to observe if the cost of FN is high. So the 3rd model does better as per our business problem. So might go for 3rd model for further prediction.
Case 2: Email is spam/not spam prediction. (cost of FP > cost of FN)
class 1: spam
class 0: not spam
- the result of TP will be that spam emails are placed in the spam folder.
- the result of TN will be that important emails are received.
- the result of FP will be that important emails are placed in the spam folder.
- the result of FN will be that spam emails are received.
In case 2, which scenario do you think will have the highest cost?
Well, since missing important emails will clearly be more of a problem than receiving spam, we can say that in this case, FP will have a higher cost than FN.
For this example also collect 10 samples to test on the trained model as shown below,
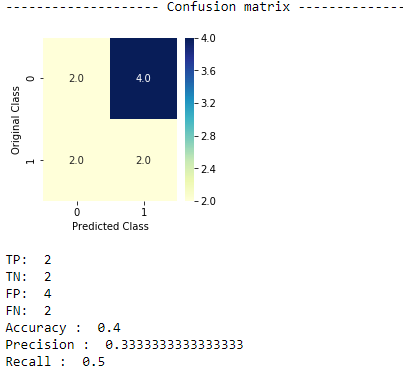

From the above code, we can see that as FP Increases Precision decreases as the precision depends on FP. So recall is the best metric to observe if the cost of FP is higher. So we might choose the 3rd model as it has less number of FP’s.
Case 3: Cancer Diagnosis (Cost of FN > Cost of FP)
class 1: cancer
class 0: not cancer
- the result of TP will be that patient has cancer and the model predicted cancer (all good).
- the result of TN will be that the model predicted the patient has no cancer and that actually true (again all good).
- the result of FP will be that patient has no cancer but diagnosed (model predicted) as cancer (class 1).
- the result of FN will be that patient has cancer but diagnosed (model predicted ) as not cancer (class 0).
In case 3, which scenario do you think will have the highest cost?
Imagine when Our model predicts (diagnosed) as the patient has no cancer but in reality, the patient has cancer i.e FN then the life of that patient is in danger as a doctor can send the patient home without any treatment.
In practice, the cost of false negatives is not the same as the cost of false positives, depending on the different specific cases or Business problems. It is evident that not only should we calculate accuracy, but we should also evaluate our model using other metrics, for example, Recall and Precision.
Combining Precision and Recall — F1 Score
In the above three cases, we want to maximize either recall or precision at the expense of the other metric. For example, in the case of cancer diagnosis classification, we would like to decrease FN to increase recall. However, in cases where we want to find an optimal blend of precision and recall, we can combine the two metrics using the F1 score.
The F1 score is a number between 0 and 1 and is the harmonic mean of precision and recall.
I think that’s the reason this is my favorite evaluation metric and I tend to use this a lot in my classification projects.


Simply stated the F1 score sort of maintains a balance between the precision and recall for your classifier. If your precision is low, the F1 is low, and if the recall is low again your F1 score is low.
If you are a police inspector and you want to catch criminals, you want to be sure that the person you catch is a criminal (Precision) and you also want to capture as many criminals (Recall) as possible. The F1 score manages this tradeoff.
The main problem with the F1 score is that it gives equal weight to precision and recall. We might sometimes need to include domain knowledge in our evaluation where we want to have more recall or more precision.
To solve this, we can do this by creating a weighted F1 metric as below where beta manages the tradeoff between precision and recall.

Here we give β times as much importance to recall as precision.
2. ROC/AUC
When our model gives probabilistic output i.e. P(y =1 | X) then very often we use threshold 0.5 to convert into integer 0 or 1. This means P(y = 1 |X)≥0.5 then classify ‘X’ as class 1 and P(y=1 |X)<0.5 then classify ‘X’ as class 0.
Now, How to decide the threshold? So now intis part how can we choose the optimal threshold to decide class.
ROC is a major visualization technique for presenting the performance of a classification model. It summarizes the trade-off between the true positive rate (tpr) and false positive rate (fpr) for a predictive model using different probability thresholds.

The true positive rate (tpr) is the recall and the false positive rate (FPR) is the probability of a false alarm.
We have got the probabilities from our classifier. We can use various threshold values to plot our sensitivity(TPR) and (1-specificity)(FPR) on the cure and we will have a ROC curve.
Below is the ROC curve for the same model at different threshold values.

From the above graph, it can be seen that the true positive rate increases at a higher rate but suddenly at a certain threshold, the TPR starts to taper off. For every increase in TPR, we have to pay a cost, the cost of an increase in FPR. At the initial stage, the TPR increase is higher than FPR
So, we can select the threshold for which the TPR is high and FPR is low.

For different models, we will have a different ROC curve. Now, how to compare different models? From the above plot, it is clear that the curve is in the upper triangle, the good the model is. One way to compare classifiers is to measure the area under the curve for ROC.

AUC(Model 1) > AUC(Model 2) > AUC(Model 2)
Thus Model 1 is the best of all.
AUC is the area under the ROC curve.
AUC ROC indicates how well the probabilities from the positive classes are separated from the negative classes
How we choose optima Threshold?
Sensitivty = TPR(True Positive Rate)= Recall = TP/(TP+FP)
1- Specificity = FPR(False Positive Rate)= FP/(TN+FP)

Here we can use the ROC curves to decide on a Threshold value. The choice of threshold value will also depend on how the classifier is intended to be used.
If it is a cancer classification application you don’t want your threshold to be as big as 0.5. Even if a patient has a 0.3 probability of having cancer you would classify him to be 1.
Another interpretation of AUC is if someone gives two points from class 0 and class 1 but I don’t know which point belongs to which class. I will pass through these points 2 points to a trained model which has AUC = 0.75, there is a 75% of probability that it is correctly classified.
How to implement in python :

3. Log Loss/Binary Crossentropy
Log loss is a pretty good evaluation metric for binary classifiers and it is sometimes the optimization objective as well in case of Logistic regression and Neural Networks.
Binary Log loss for example is given by the below formula where p is the probability of predicting 1 (P(y = 1 |X)).


As you can see the log loss decreases as we are fairly certain in our prediction of 1 and the true label is 1. This means the probability of prediction is near to the actual value. suppose for given point ‘X’ true label is 1 and model predict P(y=1|X)= 0.9 then log loss is less. It will be penalized when the prediction probability is far away from the actual class.
When to Use?
When the output of a classifier is prediction probabilities. Log Loss takes into account the uncertainty of your prediction based on how much it varies from the actual label. This gives us a more nuanced view of the performance of our model. In general, minimizing Log Loss gives greater accuracy for the classifier.
How to implement :
Caveats
It is susceptible in the case of imbalanced datasets. You might have to introduce class weights to penalize minority errors more or you may use this after balancing your dataset.
4. Categorical Crossentropy
The log loss also generalizes to the multiclass problem. The classifier in a multiclass setting must assign a probability to each class for all examples. If there are N samples belonging to M classes, then the Categorical Crossentropy is the summation of -ylogp values:

yij is 1 if the sample i belongs to class j, else 0
pij is the probability our classifier predicts of sample i belonging to class j.
When to Use?
When the output of a classifier is multiclass prediction probabilities. We generally use Categorical Crossentropy in the case of Neural Nets. In general, minimizing Categorical cross-entropy gives greater accuracy for the classifier.
Caveats:
It is susceptible in the case of imbalanced datasets.
We see the most commonly used evaluation metrics for binary class classification now question is,
What about Multi-Class Problems?
Then how can you calculate Precision & Recall for problems with Multiple classes as labels?
Let us first consider the situation. Assume we have a 3 Class classification problem where we need to classify emails received as Urgent, Normal, or Spam.
Now let us calculate Precision & Recall for this using the below methods:
MACRO AVERAGING:

- [urgent,normal]=10 means 10 normal(actual label) mails has been classified as urgent.
- [spam,urgent]=3 means 3 urgent(actual label) mails have been classified as spam
So the calculation is shown in the above figure for precision and recall.
Macro-average precision = (precision_u,precision_n,precision_s)/3
Similarly, we calculate a Macro-average recall.
So, F1 = (2 * Macro-average precision *Macro-average recall ) / (Macro-average recall+Macro-average precision)
Micro-average Method :
In the Micro-average method, you sum up the individual true positives, false positives, and false negatives of the system for different sets and apply them to get the statistics. For example, for a set of data, the system’s
True positive (TP1) = 12
False positive (FP1) = 9
False negative (FN1) = 3and for a different set of data, the system’s
True positive (TP2) = 50
False positive (FP2) = 23
False negative (FN2) = 9Micro-average of precision=(TP1+TP2)/(TP1+TP2+FP1+FP2)=12+5012+50+9+23=65.96
Micro-average of recall=(TP1+TP2)/(TP1+TP2+FN1+FN2)=12+5012+50+3+9=83.78
The Micro-average F-Score will be simply the harmonic mean of these two figures.
Summary
We have learned different metrics used to evaluate the classification models. When to use which metrics depends primarily on the nature of your problem. So get back to your model now, question yourself what is the main purpose you are trying to solve, select the right metrics, and evaluate your model.
References :
https://machinelearningmastery.com/tour-of-evaluation-metrics-for-imbalanced-classification/
Happy Learning !!!
